Evitando alocações de memória ao ler arquivos textos
Esta é uma tarefa comum, alguns processos de importação e exportação de dados usam colunas fixas, como alguns usados por bancos, por exemplos o CNAB.
O processo de leitura parece simples e realmente é. Só precisamos tomar alguns cuidados, como não ter ler todo o arquivo para a memória para então processar e guardar seu resultado, o que poderia causar um OutOfMemoryException.
De forma geral, bastaria algo como:
int[] positions = new int[] { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
string[] result = new string[positions.Length];
using (StreamReader sr = new StreamReader("Data.txt"))
{
string line;
while ((line = sr.ReadLine()) != null)
{
int lastIndex = 0;
for (int i = 0; i < positions.Length; i++)
{
result[i] = line.Substring(lastIndex, positions[i]);
lastIndex += positions[i];
}
}
}
Porém desta forma são alocadas diversas string para cada linha. Cada chamada ao método Substring, cria uma nova string.
Assim, ao ler 1.000.000 de linhas, são alocados cerca de 1121MB levando 1208ms.
Ao realizar o profiling da aplicação é possível ver que a praticamente todo o tempo é utilizado nos métodos ReadLine e Substring. (Não foi possível aguardar o fim da execução, com o profiler ativo ela fica muito mais lenta)
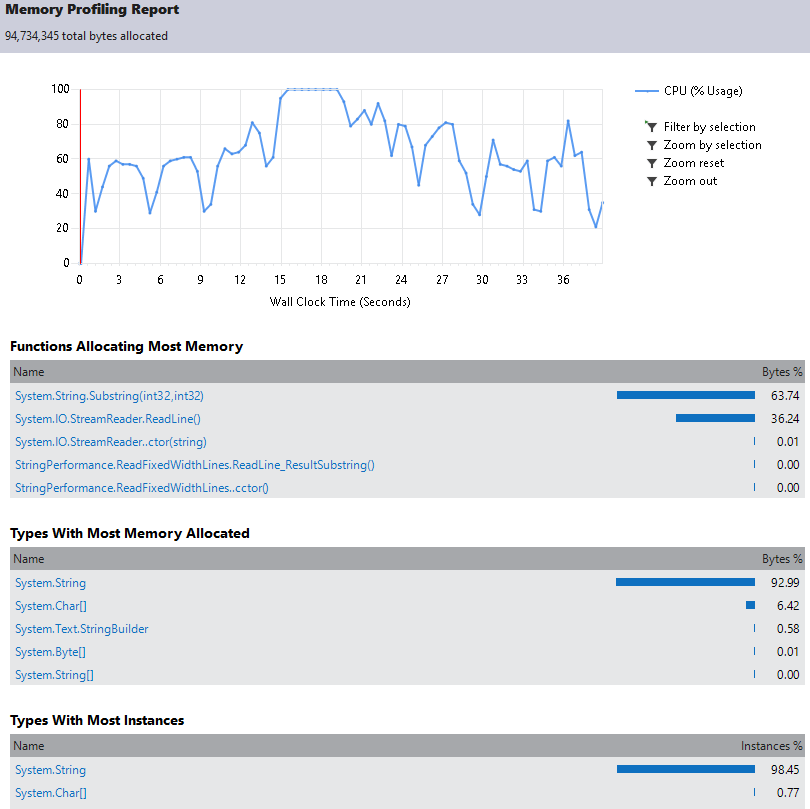
Assim podemos tentar otimizar estes dois pontos, o primeiro deles, o uso de Substring.
Neste exemplo criei duas soluções, utilizando char[], no caso como são diversas colunas, char[][]. A segunda opção com ponteiros.
Ambas tem resultados semelhantes, cada uma com seus pontos fortes e fracos. Ao utilizar ponteiro você obrigatoriamente utiliza código marcado como unsafe. E ao utilizar char[] não é possível utilizar as classes do .NET para fazer o Parse para int por exemplo, apesar de ser possível criar seu próprio método, como o método privado do .NET: https://referencesource.microsoft.com/#mscorlib/system/number.cs,04291cc3a0b10032,references
Ao executar o teste sem SubString diminuimos para 412MB alocados e 915ms de execução:
public void ReadLine_ResultCharArray()
{
char[][] result = new char[positions.Length][];
//Allocate char array of right size
for (int i = 0; i < positions.Length; i++)
{
result[i] = new char[positions[i]];
}
using (TextReader sr = GetReader())
{
string line;
while ((line = sr.ReadLine()) != null)
{
int lastIndex = 0;
for (int i = 0; i < positions.Length; i++)
{
int fieldLength = positions[i];
for (int j = 0; j < fieldLength; j++)
{
result[i][j] = line[lastIndex + j];
}
lastIndex += fieldLength;
}
}
}
}
Desta vez o profiling é executado quase que de forma instantânea:
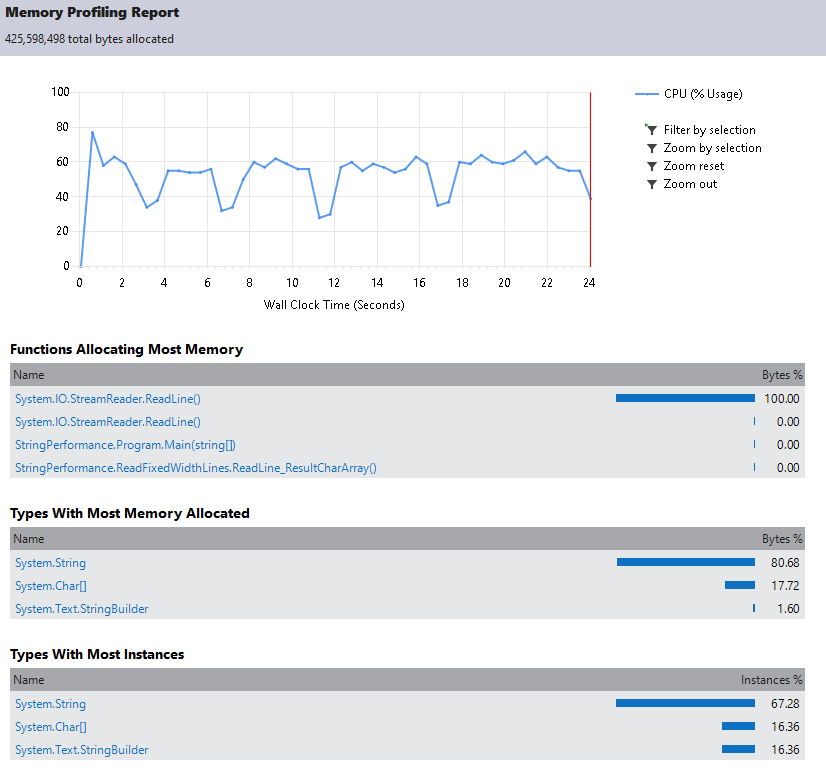
Agora nosso foco é o método ReadLine.
A classe TextReader possui um método Read que permite que seja utilizado um buffer de char[], assim podemos usar este método para evitar alocações, criando um buffer do tamanho de uma linha e reutilizando até o final do processamento:
public void Read_ResultCharArray()
{
int bufferSize = GetLineSize();
char[] buffer = new char[bufferSize];
char[][] result = new char[positions.Length][];
//Allocate char array of right size
for (int i = 0; i < positions.Length; i++)
{
result[i] = new char[positions[i]];
}
using (TextReader sr = GetReader())
{
while (sr.Read(buffer, 0, bufferSize) > 0)
{
int lastIndex = 0;
for (int i = 0; i < positions.Length; i++)
{
int fieldLength = positions[i];
for (int j = 0; j < fieldLength; j++)
{
result[i][j] = buffer[lastIndex + j];
}
lastIndex += fieldLength;
}
}
}
}
Diminuindo a alocação de memória para valores irrisórios:
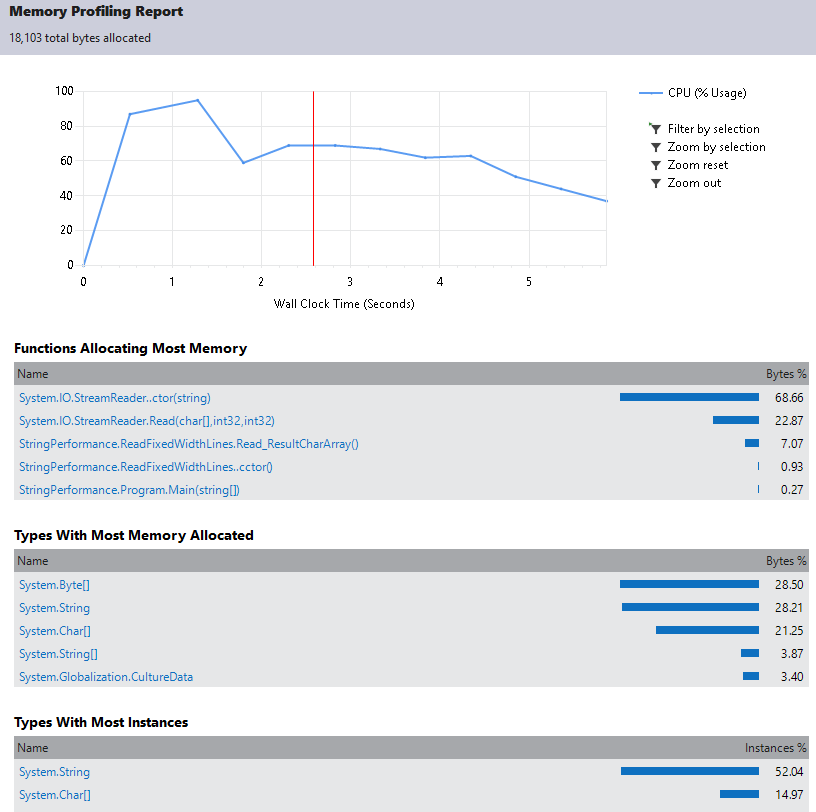
Desta forma porém nosso resultado é um array de char e não string, impedindo o uso de alguns métodos como int.Parse. Para continuarmos com o resultado em string, é possível utilizando ponteiros, como no exemplo:
public void Read_ResultUseUnsafeCharPointer()
{
int bufferSize = GetLineSize();
char[] buffer = new char[bufferSize];
string[] result = new string[positions.Length];
//Allocate empty strings of right size
for (int i = 0; i < positions.Length; i++)
{
result[i] = new string(' ', positions[i]);
}
using (TextReader sr = GetReader())
{
while (sr.Read(buffer, 0, bufferSize) > 0)
{
int lastIndex = 0;
for (int i = 0; i < positions.Length; i++)
{
int fieldLength = positions[i];
unsafe
{
fixed (char* chars = result[i])
{
for (int j = 0; j < fieldLength; j++)
{
chars[j] = buffer[lastIndex + j];
}
}
}
lastIndex += fieldLength;
}
}
}
}
O uso de memória e tempo de processamento é semelhante ao usar char[][].
Abaixo um sumário com todos os testes realizados com 100 mil linhas:
| Method | Mean | StdErr | StdDev | Median | Scaled | Scaled-StdDev | Gen 0 | Bytes Allocated/Op |
|---|---|---|---|---|---|---|---|---|
| GoStraightReadLine | 68.5477 ms | 0.4298 ms | 0.7444 ms | 68.7090 ms | 0.49 | 0.00 | 2,268.00 | 101,400,456.33 |
| GoStraightRead | 34.3965 ms | 0.3196 ms | 0.5535 ms | 34.4998 ms | 0.25 | 0.00 | - | 19,869.67 |
| ReadLine_ResultSubstring | 140.3299 ms | 0.0818 ms | 0.1416 ms | 140.3629 ms | 1.00 | 0.00 | 6,440.00 | 284,255,469.00 |
| ReadLine_ResultCharArray | 101.1819 ms | 0.6428 ms | 1.1134 ms | 100.8166 ms | 0.72 | 0.01 | 2,275.00 | 101,735,538.92 |
| ReadLine_ResultUseUnsafeCharPointer | 106.5311 ms | 0.2403 ms | 0.4162 ms | 106.3192 ms | 0.76 | 0.00 | 2,275.00 | 101,738,164.83 |
| Read_ResultNewString | 109.9989 ms | 0.0806 ms | 0.1395 ms | 110.0615 ms | 0.78 | 0.00 | 4,165.00 | 182,531,333.17 |
| Read_ResultUseUnsafeCharPointer | 80.7485 ms | 0.2625 ms | 0.4546 ms | 80.7316 ms | 0.58 | 0.00 | - | 24,451.50 |
| Read_ResultCharArray | 77.3640 ms | 1.0972 ms | 1.9004 ms | 76.4365 ms | 0.55 | 0.01 | - | 24,806.92 |
As duas primeiras linhas representam a leitura do arquivo, sem nenhum processamento. A terceira é o primeiro exemplo e a última o último exemplo


