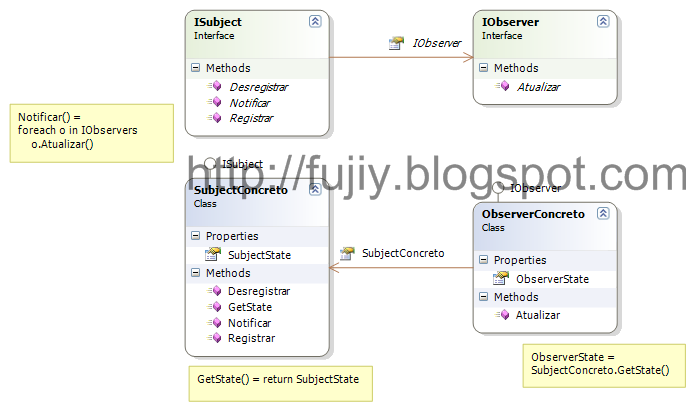
Design Patterns com certeza é um dos assuntos em que tenho mais interesse. Depois que você começa a estudá-los passa a pensar de forma diferente na hora de programar.
Há muito tempo vejo que cada vez que começava a escrever algum programa e o código ia crescendo e ficando mais complexo ficava muito difícil fazer alguma alteração, e testar tudo de novo. Isso quando era possível fazer alguma mudança ou extensão de forma viável.
Definição da Wikipedia:
In software engineering, a design pattern is a general reusable solution to a commonly occurring problem in software design. A design pattern is not a finished design that can be transformed directly into code. It is a description or template for how to solve a problem that can be used in many different situations. Object-oriented design patterns typically show relationships and interactions between classes or objects, without specifying the final application classes or objects that are involved. Algorithms are not thought of as design patterns, since they solve computational problems rather than design problems.
Not all software patterns are design patterns. Design patterns deal specifically with problems at the level of software design. Other kinds of patterns, such as architectural patterns, describe problems and solutions that have alternative scopes.
Em português:
Na engenharia de software, um design pattern é uma solução geral reutilizável para um problema que ocorre comumente na concepção do software. Um design pattern não é um projeto acabado que possa ser diretamente transformado em código. É uma descrição ou modelo de como resolver um problema que pode ser usado em muitas situações diferentes. Design patterns em orientação à objetos tipicamente mostra os relacionamentos e interações entre classes ou objetos, sem especificar a aplicação final das classes ou objetos envolvidos. Algoritmos não são consideradas design patterns, pois eles resolvem problemas computacionais em vez de problemas de design.
Perceba que nem todos software patterns são design patterns. Design patterns lidam especificamente com problemas no nível de design de software. Outros tipos de padrões, como architectural patterns, descrevem problemas e soluções que tem escopos alternativos.
Vamos começar pelo mais simples deles, o Singleton. Que apesar de ser simples tem alguns problemas no qual precisamos ficar atentos, no caso com Multi-Thread.
O padrão Singleton deve garantir que uma classe tenha uma única instância e proporcione um ponto de acesso global.
Um exemplo de uso é no caso de um objeto de log, deixando uma única instância responsável por gerenciar o log.
Vemos aqui um diagrama de classe do Singleton:
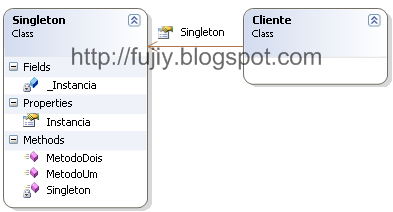
Perceba que temos um construtor private, pois não podemos deixar a classe Cliente criar novas instâncias do Singleton.
Agora apresentando o código, a princípio poderíamos criar um código bem simples como esse:
public static Singleton Instancia
{
get
{
if (_Instancia == null)
_Instancia = new Singleton();
return _Instancia;
}
}
Mas teríamos um problema, se um thread A estiver acessando o Singleton pela primeira vez e logo após o if (_Instancia == null) fosse interrompido e então um thread B poderia passar também pela condição, já que o Singleton ainda é null e então instanciar o objeto. Quando o thread A voltasse, ele estaria dentro do if, e criaria outra instância do objeto, o que não é desejado nesse deisgn pattern.
Para resolver este problema, podemos fazer um lock sobre a classe, garantindo que apenas um thread passe pelo lock. Adicionalmente criamos outro if antes do lock, para que depois que a classe estiver devidamente instanciada, não criarmos lock´s toda vez que alguém acessar a Instancia, o que degradaria a performance.
Este modelo se chama "Double Check Lock". Neste modelo, mesmo que dois ou mais threads passem pelo primeiro if, apenas um thread pode passar pelo lock por vez, então se o thread A passar pelo lock primeiro, ele vai verificar no segundo if se o objeto já foi instanciado, se não foi ele irá instanciá-lo. Quando o thread A terminar, irá liberar o lock, e o thread B então continua seu trabalho entrando no lock, mas desta vez ele não conseguirá passar pelo segundo if, pois o thread A já instanciou o objeto.
public static Singleton Instancia
{
get
{
if (_Instancia == null)
{
lock (typeof(Singleton))
{
if (_Instancia == null)
_Instancia = new Singleton();
}
}
return _Instancia;
}
}
Geralmente quem olha esse código imagina que já temos o necessário, e realmente é o que parece. Mas temos um outro problema que não é visível no código.
Quando o compilamos nosso código, várias otimizações são feitas no código assembly(no caso IL, mas o modelo é aplicável a qualquer linguagem como C++) e essa otimização pode comprometer a integridade do nosso modelo. Pra entender como isso acontece vamos revisar como um objeto é instanciado:
1º - A memória(no Heap) é alocada para guardar o objeto Singleton.
2º - O Singleton é construído dentro do espaço de memória alocado.
3º - O endereço da memória alocada é atribuído à Instância(no Stack).
*Não vou explicar como funciona o Heap e Stack nesse artigo para não perdemos o foco.
Mas o compilador pode reordenar essas instruções quando faz a otimização do código, e o problema aparece quando o passo 2 e 3 são trocados:
1º - A memória(no Heap) é alocada para guardar o objeto Singleton.
2º - O endereço da memória alocada é atribuído à Instância(no Stack).
3º - O Singleton é construído dentro do espaço de memória alocado.
Usando o mesmo exemplo, se o thread A for interrompido depois de passar pelo 2º passo, o thread B ao chegar no if (_Instancia == null) irá receber false, pois _Instancia não tem mais o valor null, já foi atribuído um endereço de memória à ele, então o objeto _Instancia será retornado do jeito que está e quando sua classe Cliente for usá-lo...teremos um erro! O objeto ainda não existe, apenas o espaço alocado na memória.
Para resolvermos este problema no C# podemos usar a keyword volatile, que diz ao processador que não deve reordenar as instruções e deixar a otimização de lado:
public class Singleton
{
private static volatile Singleton _Instancia = null;
private Singleton()
{
}
public static Singleton Instancia
{
get
{
if (_Instancia == null)
{
lock (typeof(Singleton))
{
if (_Instancia == null)
_Instancia = new Singleton();
}
}
return _Instancia;
}
}
public static void MetodoUm()
{
}
public static void MetodoDois()
{
}
}
Em .Net temos uma outra opção, muito mais simples e elegante, mas essa forma é particular do .Net não tendo nada parecido em outras linguagens:
sealed class Singleton
{
private Singleton() { }
public static readonly Singleton Instancia = new Singleton();
}
Pra começar mudamos o comportamento da classe, que tinha um "lazy initialization" e o removemos. Não estamos mais usando uma propriedade e sim dando acesso direto ao objeto Singleton, além de marcá-lo como readonly e instanciarmos na declaração.
Então esse método é pior? Perdemos a vantagem do "lazy initialization" e estamos sobre o perigo do acesso em Multi-Thread? Na verdade não, estamos apenas passando a responsabilidade pro .Net.
Sobre o "lazy initialization", antes fizemos uma propriedade que na primeira vez que era chamada criava a instância do objeto. Esse comportamento é o "lazy initialization", só instanciar o objeto quando ele for necessário, se for. O .Net faz isso pra gente, o JIT é esperto o suficiente pra instanciar a propriedade static quando e somente quando alguém usá-la.
E sobre a inicialização Thread-Safe? O readonly cuida disso, já que uma das regras sobre o readonly é que ele só possa ser inicializado de forma estática, o que só vai acontecer uma vez.
Por fim declaramos a classe como sealed, pois não é uma boa prática herdar de um Singleton, além de que se você precisar de outra implementação de Singleton é muito fácil fazer do zero, e evita muitos problemas.
Espero ter sido claro o suficiente, qualquer dúvida é só deixar um comentário. Até o próximo artigo.